Paper
Music Structure Boundaries Estimation
AES 2017
Abstract
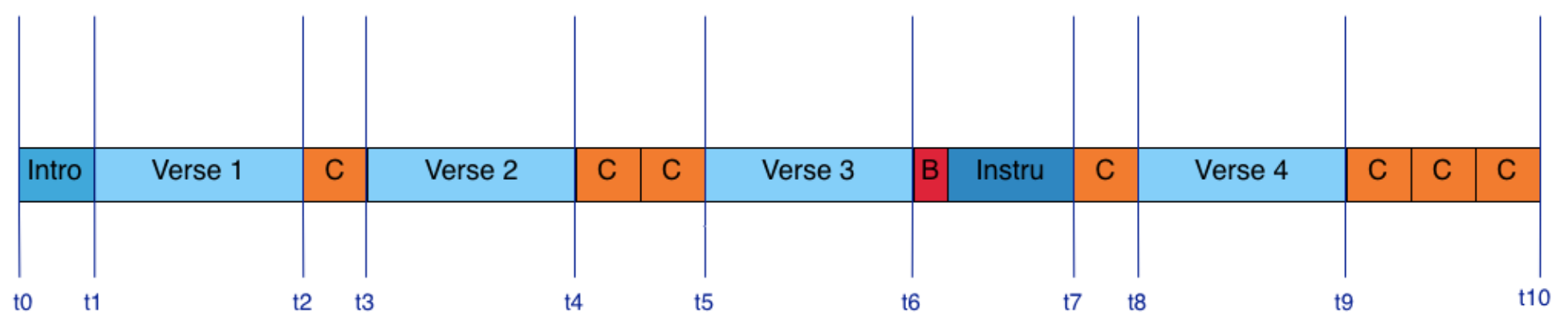
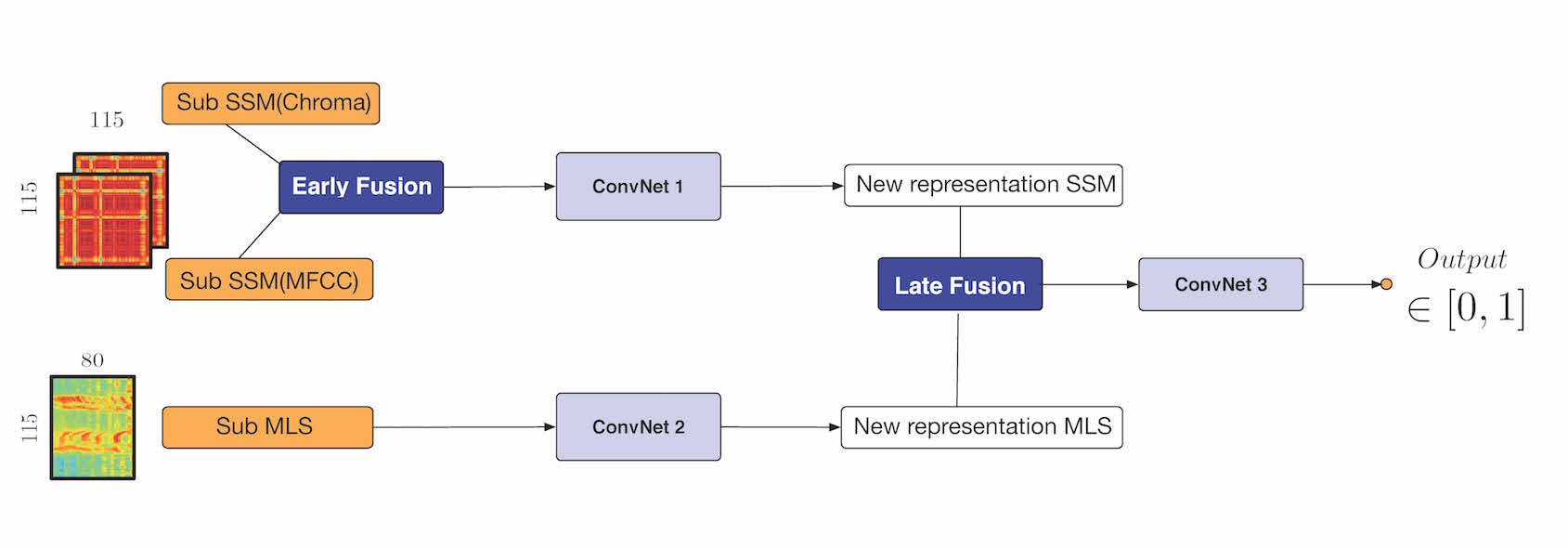
In this paper, we propose a new representation as input of a Convolutional Neural Network with the goal of estimating music structure boundaries. For this task, previous works used a network performing the late-fusion of a Mel-scaled log-magnitude spectrogram and a self-similarity-lag-matrix.
We propose here to use the square-sub-matrices centered on the main diagonals of several self-similarity-matrices, each one representing a different audio descriptors. We propose to combine them using the depth of the input layer. We show that this representation improves the results over the use of the self-similarity-lag-matrix. We also show that using the depth of the input layer provide a convenient way for early fusion of audio representations.