Paper
Source separation & data augmentation
Eusipco 2019
Abstract
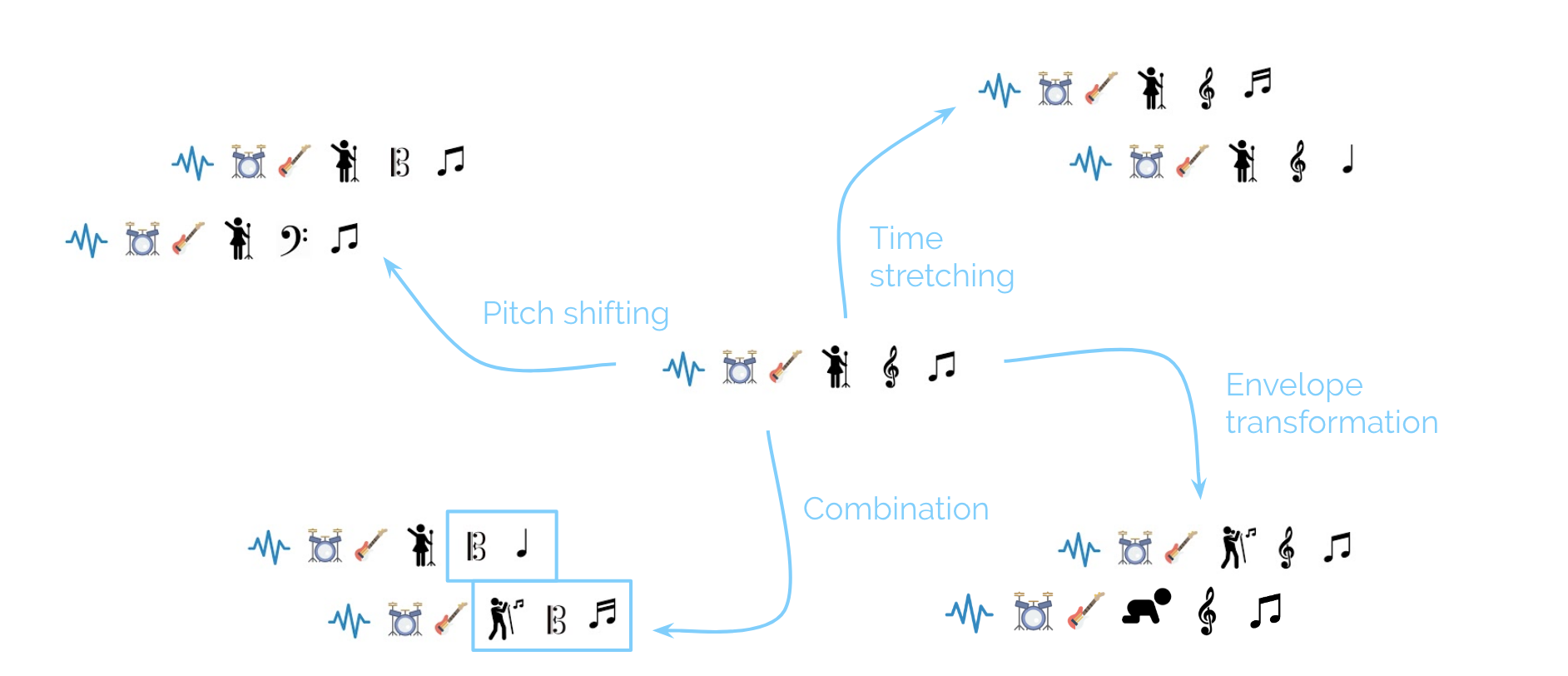
State-of-the-art singing voice separation is based on deep learning making use of CNN structures with skip connections (like U-net model, Wave-U-Net model, or MSDENSELSTM). A key to the success of these models is the availability of a large amount of training data. In the following study, we are interested in singing voice separation for mono signals and will investigate into comparing the U-Net and the Wave-U-Net that are structurally similar, but work on different input representations.
First, we report a few results on variations of the U-Net model. Second, we will discuss the potential of state of the art speech and music transformation algorithms for augmentation of existing data sets and demonstrate that the effect of these augmentations depends on the signal representations used by the model. The results demonstrate a considerable improvement due to the augmentation for both models. But pitch transposition is the most effective augmentation strategy for the U-Net model, while transposition, time stretching, and formant shifting have a much more balanced effect on the Wave-U-Net model. Finally, we compare the two models on the same dataset.