Paper
ISMIR 2018
The Dali Dataset
ISMIR 2018
Abstract
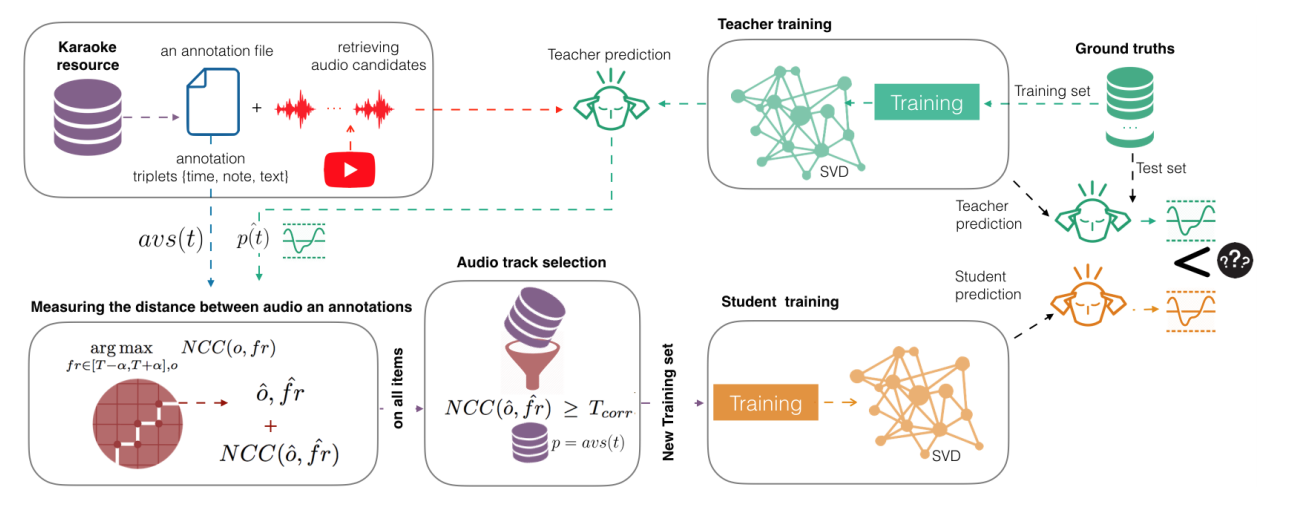
The DALI dataset is a large dataset of time-aligned symbolic vocal melody notations (notes) and lyrics at four levels of granularity. DALI contains 5358 songs in its first version and 7756 for the second one. In this article, we present the dataset, explain the developed tools to work the data and detail the approach used to build it. Our method is motivated by active learning and the teacher-student paradigm. We establish a loop whereby dataset creation and model learning interact, benefiting each other. We progressively improve our model using the collected data. At the same time, we correct and enhance the collected data every time we update the model. This process creates an improved DALI dataset after each iteration. Finally, we outline the errors still present in the dataset and propose solutions to global issues. We believe that DALI can encourage other researchers to explore the interaction between model learning and dataset creation, rather than regarding them as independent tasks.
This work has been realised in colaboration with Gabriel Meseguer Brocal.