Paper
The Dali Dataset
ISMIR 2018
Abstract
The goal of this paper is twofold. First, we introduce DALI, a large and rich multimodal dataset containing 5358 audio tracks with their time-aligned vocal melody notes and lyrics at four levels of granularity.
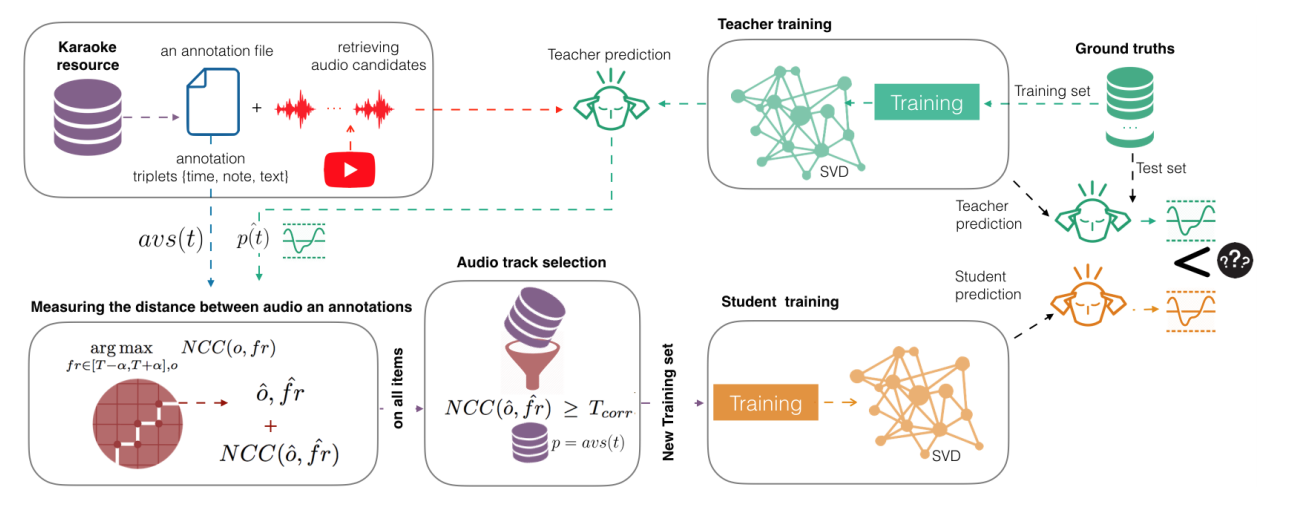
The second goal is to explain our methodology where dataset creation and learning models interact using a teacher-student machine learning paradigm that benefits each other. We start with a set of manual annotations of draft time-aligned lyrics and notes made by non-expert users of Karaoke games. This set comes without audio. Therefore, we need to find the corresponding audio and adapt the annotations to it. To that end, we retrieve audio candidates from the Web. Each candidate is then turned into a singing-voice probability over time using a teacher, a deep convolutional neural network singing-voice detection system (SVD), trained on cleaned data. Comparing the time-aligned lyrics and the singing-voice probability, we detect matches and update the time-alignment lyrics accordingly. From this, we obtain new audio sets. They are then used to train new SVD students used to perform again the above comparison. The process could be repeated iteratively. We show that this allows to progressively improve the performances of our SVD and get better audiomatching and alignment.

This work has been realised in colaboration with Gabriel Meseguer Brocal.